
Abstract
安全漏洞是网络安全威胁的根源之一。 为了发现漏洞并提前修复它们,研究人员提出了几种技术,其中模糊测试是最广泛使用的技术。 近年来,像AFL这样的模糊测试解决方案在漏洞发现方面取得了很大的进步。 本文概述了最近的进展,分析了它们如何改进模糊测试过程,并阐明了模糊测试的未来工作。 首先,我们通过比较不同的常用漏洞发现技术,讨论模糊测试流行的原因。 然后,我们概述了模糊测试解决方案,并详细讨论了一种最流行的模糊测试方法,即基于覆盖率的模糊测试。 然后,我们提出了其他技术,可以使模糊过程更智能,更高效。 最后,我们展示了一些模糊测试的应用,并讨论了模糊测试的新趋势和未来的潜在方向。
Introduction
漏洞已经成为威胁网络空间安全的根本原因。在RFC 2828(SHIRY 2000)中定义,漏洞是系统的设计、实现或操作和管理中的漏洞或弱点,这些漏洞或弱点可能被利用来违反系统的安全策略。攻击漏洞,特别是在0day漏洞,可能会造成严重损害。WANACRY RANMOSDS攻击在2017年5月爆发,该漏洞利用了服务器消息块(SMB)协议中的漏洞,据报道在一天内超过150个国家感染了超过230000台计算机。它给金融、能源、医疗等多个行业带来了严重的危机管理问题和巨大的损失。
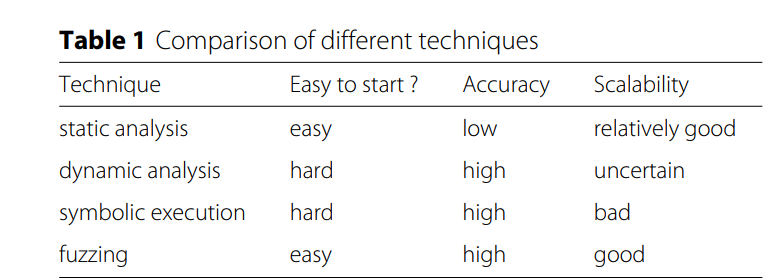
考虑到漏洞造成的严重损害,人们致力于软件和信息系统的漏洞发现技术。技术包括静态分析、动态分析、符号执行和模糊测试。与其他技术相比,模糊测试对目标的知识要求很低,可以很容易地扩展到大型应用,因此已经成为最流行的漏洞发现解决方案,尤其是在工业中。
虽然概念在几十年的发展中保持不变,但是模糊测试的执行方式已经有了很大的发展。然而,多年的实际实践表明,模糊测试倾向于在早期发现简单的内存损坏错误,并且似乎覆盖了非常小的目标代码部分。此外,模糊测试的随机性和盲目性导致发现bug的效率较低。目前已经提出了许多解决方案来提高模糊化的有效性和效率。
反馈驱动的模糊测试模式和遗传算法的结合提供了更灵活和可定制的模糊测试框架,并使模糊测试过程更加智能和高效。 凭借AFL的里程碑,反馈驱动的模糊测试,特别是覆盖率引导的模糊测试,取得了很大的进步。 受AFL的启发,最近提出了许多有效的解决方案或改进。 几年前的模糊测试跟现在有很大的不同。 因此,有必要总结近期的模糊测试工作,并阐述未来的工作。
在本文中,我们尝试总结最先进的模糊测试解决方案,以及它们如何提高漏洞发现的有效性和效率。 此外,我们还展示了传统技术如何帮助提高模糊测试的有效性和效率,并使模糊器变得更加智能。 然后,我们概述了最先进的模糊器如何检测不同目标的漏洞,包括文件格式应用程序,内核和协议。 最后,我们试图指出模糊技术发展的新趋势。
本文的其余部分组织如下:“背景”部分介绍了漏洞发现技术的背景知识,“模糊”部分详细介绍了模糊,包括模糊的基本概念和关键挑战。在“基于覆盖的模糊化”一节中,我们介绍了基于覆盖的模糊化和相关的最新研究成果。在“融合在fuzzing部分的技术”中,我们总结了其他技术如何可以帮助改进fuzzing,“面向不同应用的fuzzing”部分介绍了fuzzing的几种应用。在“模糊化的新趋势”一节中,我们讨论并总结了模糊化可能出现的新趋势。我们在“结论”部分总结我们的论文。
Background
在本节中,我们将简要介绍传统的漏洞发现技术,包括:静态分析,动态分析,污点分析,符号执行和模糊测试。然后我们总结了每种技术的优缺点。
Static analysis
静态分析是对在没有实际执行程序的情况下执行的程序的分析。相反,静态分析通常在源代码上执行,有时也在目标代码上执行。通过对词汇,语法,语义特征和数据流分析的分析,模型检查,静态分析可以检测隐藏的错误。静态分析的优点是检测速度快。分析师可以使用静态分析工具快速检查目标代码并及时执行操作。然而,静态分析在实践中要承受高错误率。由于缺乏易于使用的漏洞检测模型,静态分析工具容易出现大量误报。因此,确定静态分析的结果仍然是一项艰巨的工作。
Dynamic analysis
与静态分析相比,在程序的动态分析中,分析师需要在真实系统或仿真器中执行目标程序(Wikipedia 2017)。 通过监视运行状态并分析运行时知识,动态分析工具可以精确地检测程序错误。 动态分析的优点是精度高,但存在以下缺点, 首先,在动态分析中调试,分析和运行目标程序会导致严重的人力负担,导致效率低下。此外,人力的参与要求分析师具备很强的技术技能。总之,动态分析存在速度慢、效率低、对测试人员技术水平要求高、可扩展性差、难以进行大规模测试等缺点。
Symbolic execution
符号执行(King 1976)是另一种被认为很有前途的漏洞发现技术。通过将程序输入符号化,符号执行为每个执行路径维护了一组约束。执行之后,将使用约束求解器来求解约束,并确定是什么输入导致执行。从技术上讲,符号执行可以覆盖程序中的任意执行路径,在小程序的测试中效果良好,但也存在许多局限性。首先,路径爆炸问题,随着程序规模的增长,执行状态爆炸式增长,超出了约束求解器的求解能力,选择性符号执行被提出作为一种折衷方案。第二,环境的相互作用,在符号执行中,当目标程序执行与符号执行环境之外的组件(如系统调用、处理信号等)交互时,可能会出现一致性问题。之前的工作已经证明,符号执行仍然难以扩展到大型应用程序(Böhme et al. 2017)。
Fuzzing
Fuzzing(Sutton等人,2007)是目前最流行的漏洞发现技术。 Fuzzing最初由Barton Miller于20世纪90年代在威斯康星大学提出。从概念上讲,模糊测试从为目标应用程序生成大量正常和异常输入开始,并尝试通过将生成的输入提供给目标应用程序并监视执行状态来检测异常。与其他技术相比,模糊测试易于部署且具有良好的可扩展性和适用性,并且可以在有或没有源代码的情况下执行。此外,由于在实际执行中进行模糊测试,因此获得了高精度。更重要的是,模糊测试需要很少的目标应用程序的知识,可以很容易地扩展到大规模的应用程序。虽然模糊技术存在着效率低、代码覆盖率低等缺点,但是,模糊技术已经成为目前最有效、最高效的最先进的漏洞发现技术。表1显示了不同技术的优点和缺点。
Fuzzing
在本节中,我们尝试对模糊测试给出一个观点,包括基本技术背景知识和改进模糊测试的挑战。
Working process of fuzzing
图1描述了传统模糊测试的主要过程。 工作过程由四个主要阶段组成:测试用例生成阶段,测试用例运行阶段,程序执行状态监视和异常分析。
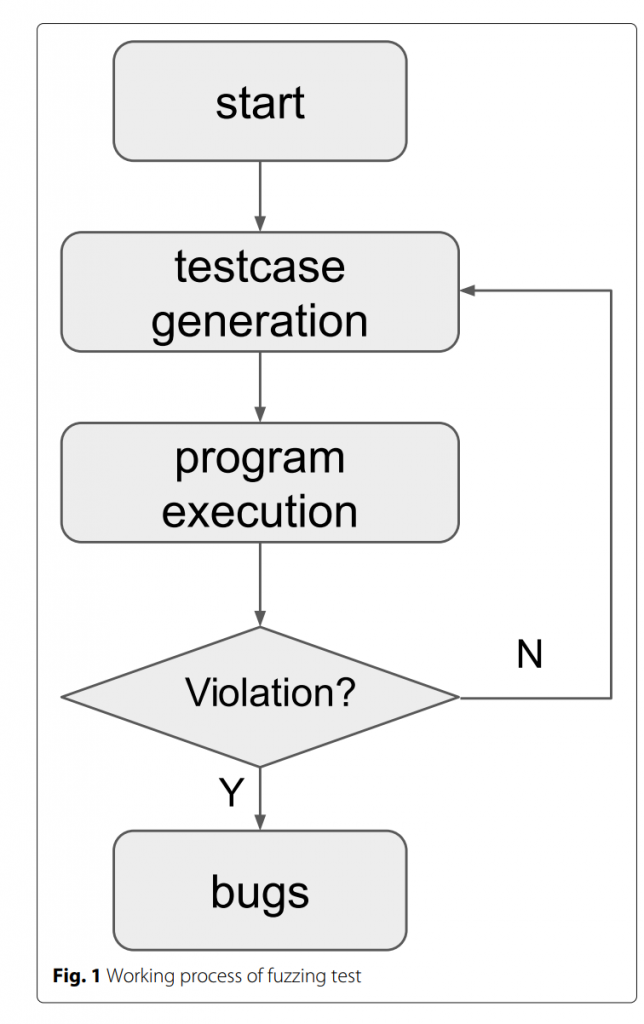
模糊测试从一堆程序输入(即测试用例)的生成开始。 生成的测试用例的质量直接影响测试效果。 输入应尽可能满足测试程序的输入格式要求。 另一方面,输入应该被打破,以便对这些输入的处理很可能使程序失败。 根据目标程序,输入可以是具有不同文件格式的文件,网络通信数据,具有指定特征的可执行二进制文件等。如何生成足够破碎的测试用例是模糊器的主要挑战。 通常,基于生成的fuzz和基于变异的fuzz在最先进的模糊器会得到应用。
在前一阶段生成后,将测试用例输入目标程序。 Fuzzers自动启动和完成目标程序进程并驱动目标程序的测试用例处理过程。 在执行之前,分析人员可以配置目标程序的开始和结束方式,并预定义参数和环境变量。 通常,模糊测试过程停止在预定义的超时,程序执行挂起或崩溃。
Fuzzers在执行目标程序期间监视执行状态,期待异常和崩溃。 常用的异常监视方法包括监视特定的系统信号,崩溃和其他违规。 对于没有直观程序异常行为的违规行为,可以使用许多工具,包括AddressSanitizer(Serebryany等人2012),DataFlowsanitizer(The Clang Team 2017a),ThreadSanitizer(Serebryany和Iskhodzhanov 2009),LeakSanitizer(The Clang Team 2017b)等 当捕获违规时,模糊器会存储相应的测试用例,以便进行后续重放和分析。
在分析阶段,分析人员试图确定捕获违规的位置和根本原因。分析通常在调试器(如GDB、windbg)或其他二进制分析工具(如ida Pro、OllyDbg)的帮助下进行。二进制工具,比如Pin (Luk et al. 2005),也可以用来监视收集到的测试用例的确切执行状态,比如线程信息、指令、寄存器信息等等。自动碰撞分析是另一个重要的研究领域。
Types of fuzzers
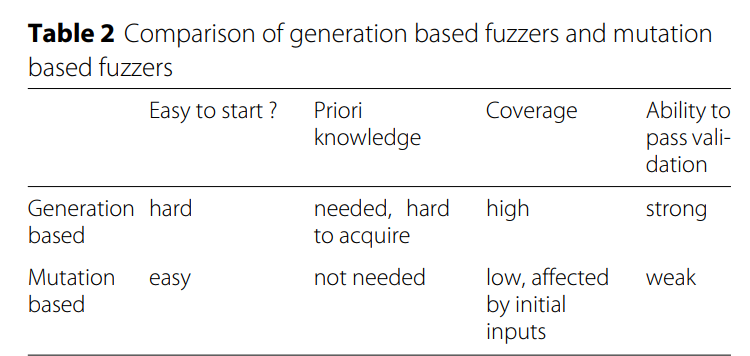
模糊器可以分为基于生成和基于突变(Van Sprundel 2005)。 对于基于生成的模糊器,需要了解程序输入。 对于文件格式模糊测试,通常会提供预定义文件格式的配置文件。 根据配置文件生成测试用例。 利用给定的文件格式知识,基于生成的模糊器生成的测试用例能够更轻松地通过程序验证,并且更有可能测试目标程序的更深层代码。 但是,如果没有友好的文档,分析文件格式是一项艰巨的工作。 因此,基于变异的模糊器更容易启动并且更适用,并且被最先进的模糊器广泛使用。 对于基于变异的模糊器,需要一组有效的初始输入。 通过在模糊测试过程中生成的初始输入和测试用例的变异来生成测试用例。 我们比较表2中基于生成的模糊器和基于变异的模糊器。
关于对程序源代码的依赖性和程序分析的程度,可以将模糊器分类为白盒,灰盒和黑盒。 假设白盒模糊器可以访问程序的源代码,因此可以通过分析源代码以及测试用例如何影响程序运行状态来收集更多信息。 黑盒模糊器在目标程序内部没有任何知识的情况下进行模糊测试。 灰盒模糊器也可以在没有源代码的情况下工作,并通过程序分析获取目标程序的内部信息。 我们在表3中列出了一些常见的白盒子,灰盒子和黑盒子模糊器。

根据探索程序的策略,模糊器可以被分类为定向模糊测试和基于覆盖的模糊测试。 定向模糊器旨在生成涵盖目标代码和程序目标路径的测试用例,并且基于覆盖的模糊器旨在生成尽可能多地涵盖程序代码的测试用例。 定向模糊器期望对程序进行更快速的测试,基于覆盖的模糊测试器期望更全面的测试和检测尽可能多的错误。 对于定向模糊器和基于覆盖的模糊器,如何提取执行路径的信息是一个关键问题。
根据程序执行状态监视和测试用例生成之间是否存在反馈,可将Fuzzers归类为哑模糊和智能模糊。 智能模糊器根据收集的测试用例如何影响程序行为来调整测试用例的生成。 对于基于变异的模糊器,反馈信息可用于确定应该变异哪些测试用例以及改变它们的方式。 哑模糊器获得了更好的测试速度,而智能模糊器可以生成更好的测试用例并获得更高的效率。
Key challenges in fuzzing
传统的模糊器通常在实践中使用基于随机的模糊测试策略。 程序分析技术的局限性导致目前的情况是模糊器不够智能。 因此,模糊测试仍面临许多挑战。 我们列出了一些主要挑战如下。
如何变异种子输入的挑战。基于变异的模糊生成策略因其方便、易于设置而被广泛应用于当前最先进的模糊算法中。然而,如何变异和生成能够覆盖更多程序路径和更容易触发bug的测试用例是一个关键的挑战(Yang et al. 2007)。具体来说,基于突变的模糊器需要回答两个问题,即何时发生突变:(1)在哪里发生突变,(2)如何发生突变。只有在少数几个关键位置发生变异才会影响执行的控制流。因此,如何在测试用例中定位这些关键位置是非常重要的。此外,模糊器对关键位置的变异也是另一个关键问题,也就是如何确定可以引导测试到程序有趣的路径的值。总之,测试用例的盲目变异会造成测试资源的严重浪费,而更好的变异策略可以显著提高模糊测试的效率。
低代码覆盖率的挑战。更高的代码覆盖率代表更高的程序执行状态覆盖率,以及更彻底的测试。以前的工作已经证明,更好的覆盖率会带来更高的找到bug的概率。然而,大多数测试用例只覆盖相同的少数路径,而大多数代码无法到达。因此,仅通过生成大量测试用例并投入测试资源来实现高覆盖率并不是一个明智的选择。基于覆盖率的模糊器试图通过程序分析技术(如程序探测)的帮助来解决问题。我们将在下一节详细介绍。
通过验证的挑战。程序通常在解析和处理之前验证输入。验证作为程序的守卫工作,节省计算资源,并保护程序免受无效输入和恶意构造的输入所造成的损害。无效的测试用例总是被忽略或丢弃。魔术数字、魔术字符串、版本号检查和校验和是程序中常用的验证方法。由黑盒和灰盒模糊器生成的测试用例很难通过盲生成策略的验证,这导致了相当低的效率的模糊。因此,如何通过验证是另一个关键的挑战。
为了应对这些挑战,人们提出了各种各样的方法,其中既有传统技术,如程序探测和污点分析,也有新技术,如RNN和LSTM (Godefroid et al. 2017 (Rajpal et al. 2017)。这些技术如何解决这些挑战将在“在模糊中集成的技术”一节中讨论
Coverage-based fuzzing
基于覆盖的模糊策略是目前最先进的模糊系统中广泛使用的一种模糊策略,已经被证明是非常有效和高效的。为了实现深入和彻底的程序模糊,模糊器应该尝试遍历尽可能多的程序运行状态。然而,对于程序状态和程序行为的不确定性,并不存在一个简单的度量标准。此外,在流程运行期间,应该很容易确定一个好的度量标准。因此,度量代码覆盖率成为一种近似的替代解决方案。使用这样的方案,代码覆盖率的增加代表了新的程序状态。此外,通过编译的和外部的插装,代码覆盖率可以很容易地测量。然而,我们说代码覆盖率是一个近似的度量,因为在实践中,一个恒定的代码覆盖率并不表示恒定数量的程序状态。使用这个度量可能会丢失一定的信息。在本节中,我们以AFL为例,说明基于覆盖的模糊处理。
Code coverage counting
在程序分析中,程序是由基本块组成的。基本块是具有单一入口和出口点的代码段,基本块中的指令将按顺序执行,并且只执行一次。在代码覆盖度量中,最先进的方法将基本块作为最佳粒度。原因包括:(1)基本块是程序执行的最小相干单位,(2)测量功能或指令会导致信息丢失或冗余,(3)基本块可以被第一个指令的地址确认和基本块的信息可以很容易通过代码插装提取。
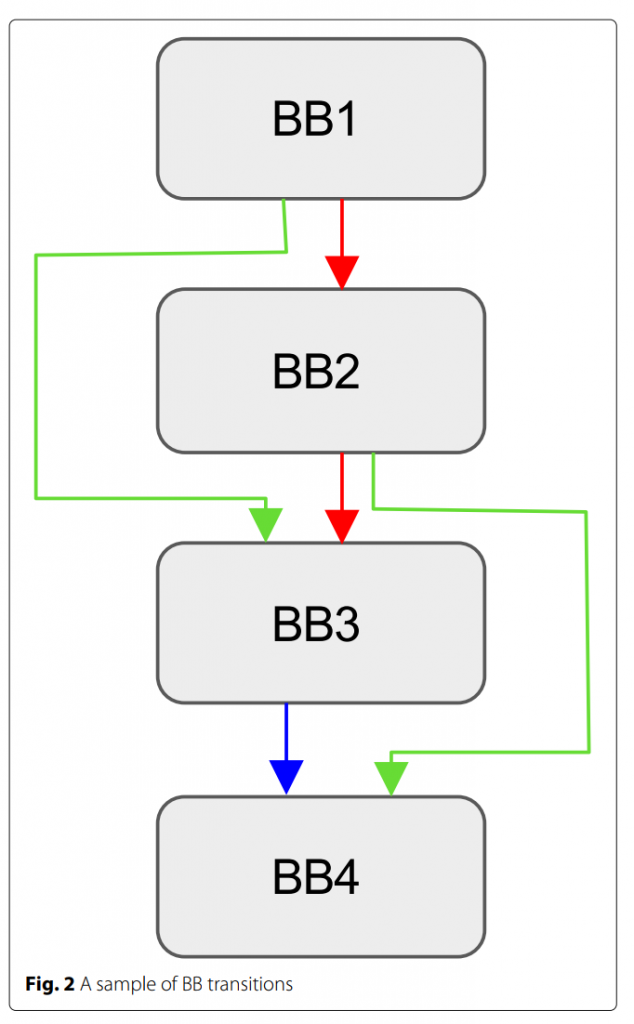
目前,有两种基于基本块的基本度量选择,简单地计算执行的基本块和计算基本块转换。在后一种方法中,程序被解释为一个图形,顶点被用来表示基本块,边被用来表示基本块之间的转换。后一种方法记录边,前一种方法记录顶点。而实验表明,简单地计算已执行的基本块会导致严重的信息丢失。如图2所示,如果先执行程序路径(BB1, BB2, BB3, BB4),再执行时遇到路径(BB1, BB2, BB4),则丢失了新的边(BB2, BB4)信息。
AFL是第一个将边缘测量方法引入到基于覆盖的模糊处理中。我们以AFL为例,说明了基于覆盖的模糊器如何在模糊过程中获得覆盖信息。AFL通过轻量级程序插桩获取覆盖信息。根据是否提供源代码,AFL提供了两种插装模式,即编译插装和外部插装。在编译工具模式下,AFL同时提供gcc模式和llvm模式,这取决于我们使用的编译器,它将在生成二进制文件时检测代码片段。在外部模式下,AFL提供qemu模式,当基本块转换为TCG块时,qemu模式将检测代码片段。
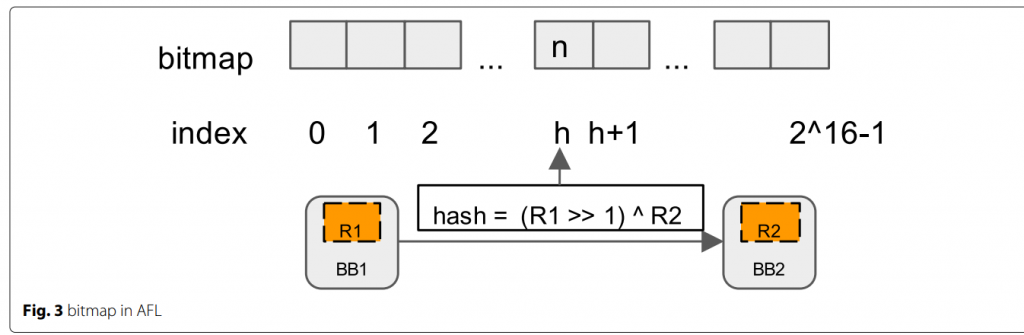
清单1显示了被插装的代码片段(Zalewski 2017b)的草图。在检测中,一个随机ID,即变量cur_location被插入在基本块中。变量shared_mem数组是一个64kb的共享内存区域,每个字节被映射到一个特定的边(BB_src, BB_dst)。当基本块转换发生时,会计算一个哈希数且位图数组中的字节值将被更新。图3描述了哈希和位图的映射。

Working process of coverage-based fuzzing
算法1给出了基于覆盖的模糊器的一般工作过程。测试从初始给定的种子输入开始。如果种子输入集没有给定,那么模糊器自己构造一个。在主模糊循环中,模糊器反复选择一个有趣的种子进行后续的变异和测试用例生成。然后在模糊器的监视下驱动目标程序执行生成的测试用例。触发崩溃的测试用例将被收集,其他有趣的测试用例将被添加到种子池中。对于基于覆盖率的模糊,到达新的控制流边缘的测试用例被认为是有趣的。主模糊回路在预先配置的超时或中止信号时停止。

在模糊过程中,模糊器通过各种方法跟踪执行情况。基本上,模糊器跟踪执行有两个目的,代码覆盖和安全违规。代码覆盖信息用于进行彻底的程序状态探索,而安全违规跟踪是为了更好地发现错误。正如在前面的小节中所详述的,AFL通过代码检测和AFL位图来跟踪代码覆盖率。安全违规跟踪可以在大量杀毒软件的帮助下进行,如AddressSanitizer (Serebryany et al. 2012)、ThreadSanitizer (Serebryany and Iskhodzhanov 2009)、LeakSanitizer (the Clang Team 2017b)等
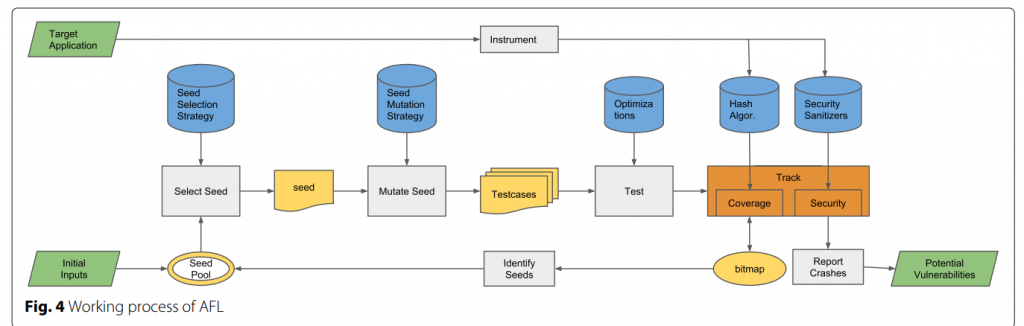
图4展示了一种非常有代表性的基于覆盖的模糊器AFL的工作过程。目标应用程序在执行覆盖率收集之前被检测。如前所述,AFL支持编译时检测和外部检测,使用gcc/llvm模式和qemu模式。还应提供初步的种子投入。在主模糊循环中,(1)模糊器根据种子选择策略从种子库中选择一个最喜欢的种子,AFL选择速度最快、最小的种子。(2)根据变异策略对种子文件进行变异,生成一组测试用例。AFL目前采用了一些随机修改和测试用例拼接方法,包括可变长度和步进的顺序位翻转、小整数的顺序加减和已知感兴趣的整数的顺序插入,如0、1、INT_MAX、等(Zalewski 2017b)(3)执行测试用例,并跟踪执行。覆盖信息被收集来确定有趣的测试用例,即到达新的控制流边缘的测试用例。有趣的测试用例被添加到下一轮运行的种子池中。
Key questions
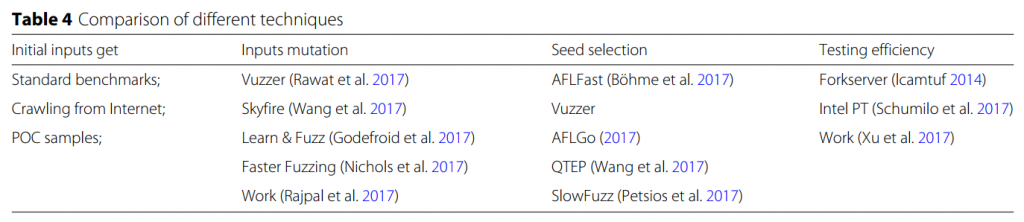
前面的介绍表明,要实现高效和有效的基于覆盖的模糊处理,需要解决许多问题。围绕这些问题,人们做了很多探索。在本小节中,我们总结并列出了一些最先进的工作,如表4所示。
A.如何获得初始投入?大多数最先进的基于覆盖的模糊算法采用基于突变的测试用例生成策略,这严重依赖于初始种子输入的质量。良好的初始种子投入可以显著提高模糊化的效率和效果。(2)良好的初始输入可以满足在突变阶段难以猜测的复杂文件格式的要求;(3)基于格式良好的种子输入的突变更有可能生成可以达到更深层次和难以达到的路径的测试用例,(4)良好的种子输入可以在多次测试中重用。
收集种子输入的常用方法包括使用标准基准、从Internet上爬取和使用现有的POC样本。开源应用程序通常以标准基准发布,可免费用于测试项目。提供的基准是根据应用程序的特性和功能构建的,这自然构建了一组良好的种子输入。考虑到目标应用程序输入的多样性,从互联网上爬取是最直观的方法。您可以轻松下载特定格式的文件。此外,对于一些常用的文件格式,网络上有很多开放的测试项目,提供免费的测试数据集。此外,使用现有的 POC 样本也是一个好主意。然而,过多的种子输入会导致在第一次试运行中浪费时间,从而带来另一个问题,如何提取初始语料。 AFL 提供了一种工具,它提取实现相同代码覆盖率的最小输入集。
B.如何生成测试用例?测试用例的质量是影响模糊测试效率和效果的重要因素。首先,好的测试用例会在更短的时间内探索更多的程序执行状态并覆盖更多的代码。此外,好的测试用例可以针对潜在的易受攻击的位置并更快地发现程序错误。因此,如何根据种子输入生成好的测试用例是一个重要的问题。拉瓦特等人。 (2017) 提出了 Vuzzer,这是一种集成了静态和动态分析的应用感知灰盒模糊器。种子输入的变异涉及两个关键问题:在哪里变异以及用于变异的值。具体来说,Vuzzer 在主模糊测试循环之前通过静态分析提取影响控制流的即时值、魔术值和其他特征字符串。在程序执行过程中,Vuzzer 利用动态污点分析技术收集影响控制流分支的信息,包括具体值和相应的偏移量。通过收集值的变异和识别位置的变异,Vuzzer 可以生成更可能满足分支判断条件并通过幻值验证的测试用例。但是,Vuzzer 仍然无法通过程序中的其他类型的验证,例如基于哈希的校验和。此外,Vuzzer 的仪器、污点分析和主模糊测试循环是基于 Pin (Luk et al. 2005) 实现的,与 AFL 相比,这导致测试速度相对较慢。
王等人。 (2017) 提出了 Skyfire,一种数据驱动的种子生成解决方案。 Skyfire 从爬取的输入中学习概率上下文敏感语法 (PCSG),并在生成结构良好的输入时利用所学知识。实验表明,Skyfire 生成的测试用例比 AFL 生成的测试用例覆盖的代码更多,发现的错误也更多。该工作还证明,测试用例的质量是影响模糊测试效率和有效性的重要因素。
随着机器学习技术的发展和广泛应用,一些研究尝试使用机器学习技术来辅助测试用例的生成。 Godefroid 等。 (2017) 来自 Microsoft Research 使用基于神经网络的统计机器学习技术来自动生成测试用例。具体来说,他们首先通过机器学习技术从一堆有效输入中学习输入格式,然后利用学到的知识指导测试用例的生成。他们在 Microsoft 的 Edge 浏览器中的 PDF 解析器上展示了一个模糊测试过程。虽然实验没有给出令人鼓舞的结果,但它仍然是一个很好的尝试。拉杰帕尔等人。 (2017) 来自 Microsoft 使用神经网络从过去的模糊探索中学习并预测输入文件中要变异的字节。尼科尔斯等人。 (2017) 使用生成对抗网络 (GAN) 模型来帮助使用新的种子文件重新初始化系统。实验表明,GAN 比 LSTM 更快、更有效,并有助于发现更多的代码路径。
C.如何从池中选择种子?模糊器在主模糊循环中的新一轮测试开始时重复从种子池中选择种子以进行变异。如何从池中选择种子是模糊测试中另一个重要的公开问题。先前的工作证明,良好的种子选择策略可以显着提高模糊测试效率,并有助于更快地发现更多错误(Rawat 等人,2017 年;Böhme 等人,2017 年,2017 年;Wang 等人,2017 年)。通过良好的种子选择策略,模糊器可以(1)优先考虑更有用的种子,包括覆盖更多代码和更容易触发漏洞,(2)减少重复执行路径的浪费并节省计算资源,(3)优化选择覆盖更深、更易受攻击的代码的种子,并帮助更快地识别隐藏的漏洞。 AFL 更喜欢更小更快的测试用例来追求更快的测试速度。
Böhme 等人。 (2017) 提出了 AFLFast,一种基于覆盖的灰盒模糊器。他们观察到大多数测试用例都集中在相同的几条路径上。例如,在 PNG 处理程序中,大多数通过随机变异生成的测试用例是无效的,并会触发错误处理路径。 AFLFast 将路径分为高频路径和低频路径。在模糊测试过程中,AFLFast 测量执行路径的频率,优先考虑模糊次数较少的种子,并将更多的能量分配给执行低频路径的种子。
拉瓦特等人。 (2017) 结合静态和动态分析来识别难以到达的更深路径,并优先考虑到达更深路径的种子。 Vuzzer 的种子选择策略可以帮助找到隐藏在深层路径中的漏洞。
AFLGo (Böhme et al. 2017) 和 QTEP (Wang et al. 2017) 采用定向选择策略。 AFLGo 将一些易受攻击的代码定义为目标位置,并优化选择更接近目标位置的测试用例。 AFLGo论文中提到了四种易受攻击的代码,包括补丁、程序崩溃缺乏足够的跟踪信息、静态分析工具验证的结果和敏感信息相关的代码片段。通过正确定向的算法,AFLGo 可以为有趣的代码分配更多的测试资源。 QTEP 利用静态代码分析来检测容易出错的源代码并优先考虑覆盖更多错误代码的种子。 AFLGo 和 QTEP 都严重依赖静态分析工具的有效性。但是,目前静态分析工具的误报率仍然很高,无法给出准确的验证。
已知漏洞的特征也可用于种子选择策略。 SlowFuzz (Petsios et al. 2017) 旨在解决算法复杂性漏洞,这通常发生在计算资源消耗非常高的情况下。因此,SlowFuzz 更喜欢消耗更多资源(如 CPU 时间和内存)的种子。然而,收集消耗资源的信息会带来沉重的开销并降低模糊测试的效率。例如,为了收集 CPU 时间,SlowFuzz 计算已执行指令的数量。此外,SlowFuzz 对资源消耗信息的准确性要求很高。
D.如何高效地测试应用程序?目标应用程序在主模糊测试循环中由模糊测试器反复启动和完成。众所周知,对于userland应用的fuzzing,进程的创建和完成会消耗大量的cpu时间。频繁的创建和完成过程会严重降低模糊测试的效率。因此,许多优化都是由以前的工作完成的。传统系统特征和新特征都用于优化。 AFL 使用 forkserver 方法,该方法创建已加载程序的相同克隆,并在每次运行时重复使用该克隆。此外,AFL 还提供持久模式,这有助于避免众所周知的缓慢的 execve() 系统调用和链接过程的开销,以及并行模式,有助于并行化多核系统上的测试。英特尔的处理器跟踪 (PT) (James 2013) 技术用于内核模糊测试,以节省覆盖跟踪带来的开销。徐等人。 (2017) 旨在解决多核机器上并行模糊测试的性能瓶颈。通过设计和实现三个新的操作原语,他们表明这些工作可以显着加速最先进的模糊器,如 AFL 和 LibFuzzer。
Techniques integrated in fuzzing
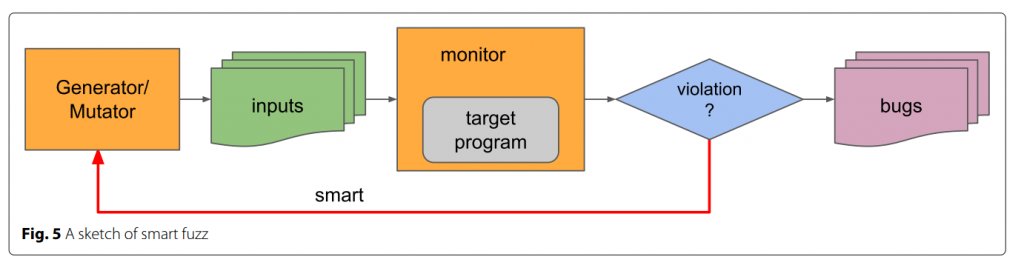
现代应用程序通常使用非常复杂的数据结构,对复杂数据结构的解析更有可能带来漏洞。使用随机变异方法的盲目模糊策略会导致大量无效测试用例和低模糊效率。目前最先进的模糊器通常采用智能模糊策略。智能模糊器通过程序分析技术收集程序控制流和数据流信息,从而利用收集到的信息来改进测试用例的生成。智能模糊器生成的测试用例更有针对性,更有可能满足程序对数据结构和逻辑判断的要求。图 5 描绘了智能模糊测试的草图。为了构建智能模糊器,在模糊测试中集成了多种技术。如前几节所述,模糊测试在实践中面临着许多挑战。在本节中,我们尝试总结以前工作中使用的技术以及这些技术如何应对模糊测试过程中的挑战。
我们在表 5 中总结了模糊测试中集成的主要技术。对于每种技术,我们在表中列出了一些代表性工作。传统技术,包括静态分析、污点分析、代码检测和符号执行,以及一些相对较新的技术,如机器学习技术,都被使用。我们选择了模糊测试的两个关键阶段,测试用例生成阶段和程序执行阶段,并总结了集成技术如何改进模糊测试。
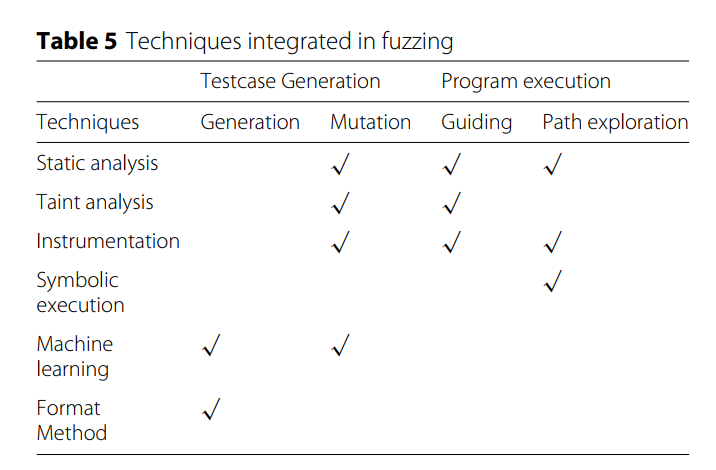
Testcase generation
如前所述,模糊测试中的测试用例是在基于生成的方法或基于变异的方法中生成的。如何生成满足复杂数据结构要求且更有可能触发难以到达的路径的测试用例是一个关键挑战。以前的工作提出了多种与不同技术相结合的对策。
在基于生成的模糊测试中,生成器根据输入数据格式的知识生成测试用例。尽管文档中提供了几种常用的文件格式,但更多的文件格式没有提供。如何获取输入的格式信息是一个硬公开问题。机器学习技术和格式方法就是用来解决这个问题的。 Work (Godefroid et al. 2017) 使用机器学习技术,特别是循环神经网络,来学习输入文件的语法,然后使用学习到的语法来生成符合格式的测试用例。 Work (Wang et al. 2017) 使用格式方法,具体来说,它定义了概率上下文相关的语法并提取格式知识以生成格式良好的种子输入。
更多最先进的模糊器采用基于突变的模糊策略。测试用例是通过修改变异过程中的部分种子输入来生成的。在盲突变模糊测试过程中,mutators 随机修改带有随机值或几个特殊值的种子字节,这被证明是非常低效的。因此,如何确定要修改的位置和修改中使用的值是另一个关键挑战。在基于覆盖的模糊测试中,应该首先修改可能影响控制流传输的字节。污点分析技术用于跟踪字节对控制流的影响,以定位突变中种子的关键字节(Rawat 等人,2017 年)。知道关键位置仅仅是个开始。 Fuzzing 过程经常在某些分支中被阻塞,包括验证和检查。比如条件判断中的magic bytes和其他值的比较。使用了包括逆向工程和污点分析在内的技术。通过扫描二进制代码并从条件判断语句中收集即时值,并将收集到的值作为变异过程中的候选值,模糊器可以通过一些关键的验证和检查,如魔术字节和版本检查。拉瓦特等人。 (2017) 机器学习技术等新技术也试图解决旧的挑战。微软的研究人员利用深度神经网络 (DNN) 等机器学习技术,根据之前通过 LSTM 的模糊测试经验,预测要变异的字节以及变异中使用的值。
Program execution
在主模糊测试循环中,目标程序被重复执行。提取程序执行状态的信息并用于改进程序执行。执行阶段涉及的两个关键问题是如何引导模糊测试过程以及如何探索新路径。
Fuzzing过程通常被引导以覆盖更多代码并更快地发现错误,因此需要路径执行信息。检测技术用于记录路径执行并计算基于覆盖的模糊测试中的覆盖信息。根据是否提供源代码,使用内置检测和外部检测。对于定向模糊测试,使用模式识别等静态分析技术来指定和识别目标代码,女巫更容易受到攻击。静态分析技术也可用于收集控制流信息,例如路径深度,可用作指导策略中的另一个参考(Rawat 等人,2017 年)。通过检测收集的路径执行信息可以帮助指导模糊测试过程。执行信息收集中还使用了一些新的系统特性和硬件特性。英特尔处理器跟踪 (Intel PT) 是英特尔处理器提供的一项新功能,它可以通过触发和过滤功能公开准确和详细的活动跟踪,以帮助隔离重要的跟踪 (James 2013)。凭借高执行速度和无源依赖的优势,英特尔 PT 可用于准确高效地跟踪执行。该功能用于 KAFL 中操作系统内核的模糊测试(Schumilo 等人,2017 年),并被证明非常有效。
测试执行的另一个问题是探索新路径。 Fuzzer在程序的控制流程中需要通过复杂的条件判断。程序分析技术包括静态分析、污点分析等,可用于识别执行中的阻塞点,以便后续解决。符号执行技术在路径探索中具有天然优势。通过求解约束集,符号执行技术可以计算满足特定条件要求的值。TaintScope (Wang et al. 2010) 利用符号执行技术来解决总是阻止模糊测试过程的校验和验证。 Driller (Stephens et al. 2016) 利用 concolic 执行绕过条件判断并找到更深层次的错误。
经过多年的发展,模糊测试变得比以往任何时候都更加细粒度、灵活和智能。反馈驱动的模糊测试提供了一种有效的引导测试方式,传统和新技术在测试执行过程中扮演传感器的角色,获取各种信息,使模糊测试准确引导。
Fuzzing towards different applications
模糊测试自出现以来就被用于检测海量应用程序的漏洞。根据不同目标应用的特点,在实践中使用不同的模糊器和不同的策略。在本节中,我们介绍并总结了几种主要的模糊测试类型的应用程序。
File format fuzzing
大多数应用程序都涉及文件处理,模糊测试被广泛用于查找这些应用程序的错误。模糊测试可以对有或没有标准格式的文件进行操作。最常用的文档文件、图像和媒体文件是具有标准格式的文件。大多数关于模糊测试的研究主要集中在文件格式模糊测试上,并提出了许多模糊测试工具,如 Peach (PeachTech 2017)、最先进的 AFL 及其扩展 (Rawat et al. 2017; Böhme et al. 2017, 2017)。之前的介绍涉及到了多种文件格式的fuzzer,其他工具这里就不赘述了。
文件格式模糊测试的一个重要子领域是在 Web 浏览器上进行模糊测试。随着网络浏览器的发展,浏览器得到扩展以支持比以往更多的功能。浏览器处理的文件类型已经从传统的 HTML、CSS、JS 文件扩展到其他类型的文件,如 pdf、svg 和其他由浏览器扩展程序处理的文件格式。具体来说,浏览器将网页解析为 DOM 树,DOM 树将网页解释为涉及事件和响应的文档对象树。特别是浏览器的DOM解析和页面渲染是目前流行的fuzzing目标。著名的 Web 浏览器模糊测试工具包括 Grinder 框架(Stephenfewer 2016)、COMRaider(Zimmer 2013)、BF3(Aldeid 2013)等。
Kernel fuzzing
在 OS 内核上进行模糊测试始终是一个涉及许多挑战的难题。首先,与用户态模糊测试不同,内核崩溃和挂起会导致整个系统瘫痪,如何捕捉崩溃是一个悬而未决的问题。其次,系统权限机制导致执行环境相对封闭,考虑到fuzzer一般运行在ring 3,如何与内核交互是另一个挑战。当前与内核通信的最佳实践是调用内核 API 函数。此外,Windows 内核和 MacOS 内核等广泛使用的内核是闭源的,很难以低性能开销进行检测。随着智能模糊测试的发展,内核模糊测试取得了一些新的进展。
通常,操作系统内核通过随机调用具有随机生成的参数值的内核 API 函数进行模糊测试。根据模糊器的侧重点,内核模糊器可以分为两类:基于知识的模糊器和覆盖引导的模糊器。
在基于知识的模糊器中,在模糊过程中利用了有关内核 API 函数的知识。具体来说,对内核 API 函数调用进行模糊测试面临两个主要挑战:(1)API 调用的参数应该具有遵循 API 规范的随机但格式良好的值,以及(2)内核 API 调用的顺序应该似乎是有效的(Han 和 Cha 2017)。代表工作包括 Trinity (Jones 2010) 和 IMF (Han and Cha 2017)。 Trinity 是一种类型感知内核模糊器。在 Trinity 中,测试用例是根据参数类型生成的。系统调用的参数根据数据类型进行修改。此外,还提供了某些枚举值和值范围以帮助生成格式良好的测试用例。 IMF 尝试学习 API 执行的正确顺序和 API 调用之间的值依赖关系,并将学到的知识用于生成测试用例。
事实证明,基于覆盖的模糊测试在查找用户级应用程序错误方面取得了巨大成功。人们开始应用基于覆盖的模糊测试方法来查找内核漏洞。代表性工作包括 syzkaller (Vyukov 2015)、TriforceAFL (Hertz 2015) 和 kAFL (Schumilo et al. 2017)。 Syzkaller 通过编译检测内核,并在一组 QEMU 虚拟机上运行内核。在模糊测试期间会跟踪覆盖范围和安全违规行为。 TriforceAFL 是 AFL 的修改版本,支持使用 QEMU 全系统仿真进行内核模糊测试。 KAFL 利用新的硬件功能 Intel PT 来跟踪覆盖范围并且仅跟踪内核代码。实验表明,KAFL比Triforce快40倍左右,大大提高了效率。
Fuzzing of protocols
目前,很多本地应用都以B/S的方式转变为网络服务。服务部署在网络上,客户端应用程序通过网络协议与服务器通信。网络协议的安全测试成为另一个重要问题。协议中的安全问题可能导致比本地应用程序更严重的损害,例如拒绝服务、信息泄漏等。与文件格式模糊测试相比,使用协议进行合作模糊测试涉及不同的挑战。首先,服务可能会定义自己的通信协议,这些协议很难确定协议标准。此外,即使对于具有标准定义的文档化协议,遵循 RFC 文档等规范仍然非常困难。
代表性的协议模糊器包括 SPIKE,它提供了一组工具,允许用户快速创建网络协议压力测试器。 Serge Gorbunov 和 Arnold Rosenbloom 提出了 AutoFuzz(Gorbunov 和 Rosenbloom 2010),它通过构建有限状态自动机来学习协议实现,并进一步利用学到的知识来生成测试用例。格雷格班克斯等。提出了 SNOOZE(Banks 等人,2006 年),它用有状态的模糊测试方法识别协议缺陷。 Joeri de Ruiter 的工作 (De Ruiter and Poll 2015) 提出了一种协议状态模糊测试方法,该方法在状态机中描述 TLS 工作状态并根据逻辑流程处理模糊测试。以前的工作通常采用有状态的方法对协议工作过程进行建模,并根据协议规范生成测试用例。
New trends of fuzzing
作为一种检测漏洞的自动化方法,模糊测试已经显示出其高效性和效率。然而,正如前几节所提到的,仍然有很多挑战需要解决。本节我们简单介绍一下自己的理解,以供参考。
首先,智能fuzzing为fuzzing的改进提供了更多的可能性。在之前的工作中,传统的静态和动态分析被集成到模糊测试中以帮助改进这个过程。有一定的改进,但有限。智能fuzzing通过多种首先,智能fuzzing为fuzzing的改进提供了更多的可能性。在之前的工作中,传统的静态和动态分析被集成到模糊测试中以帮助改进这个过程。有一定的改进,但有限。智能fuzzing通过多种方式收集目标程序执行信息,对fuzzing过程提供了更精细的控制,并提出了很多fuzzing策略。随着对不同类型漏洞的更深入了解,并利用fuzzing中漏洞的特性,smart fuzzing可以帮助发现更复杂的漏洞。
其次,新技术可以在许多方面帮助改善脆弱性。新技术,如机器学习和相关技术,已被用于改进模糊测试中的测试用例生成。如何将新技术的优点和特点与fuzzing结合起来,如何将fuzzing的关键挑战转化或拆分为新技术擅长的问题,是另一个值得思考的问题。
第三,不应忽视新的系统特性和硬件特性。(Vyukov 2015)和(Schumilo 2017)的工作表明,新的硬件特性大大提高了模糊测试的效率,给了我们很好的启发。
Conclusion
Fuzzing 是目前最有效和最高效的漏洞发现解决方案。在本文中,我们对模糊测试及其最新进展进行了全面的回顾和总结。首先,我们将模糊测试与其他漏洞发现解决方案进行了比较,然后介绍了模糊测试的概念和主要挑战。我们重点介绍了最先进的基于覆盖的模糊测试,近年来取得了很大的进展。最后总结了与fuzzing相结合的技术、fuzzing的应用和可能的新趋势。